
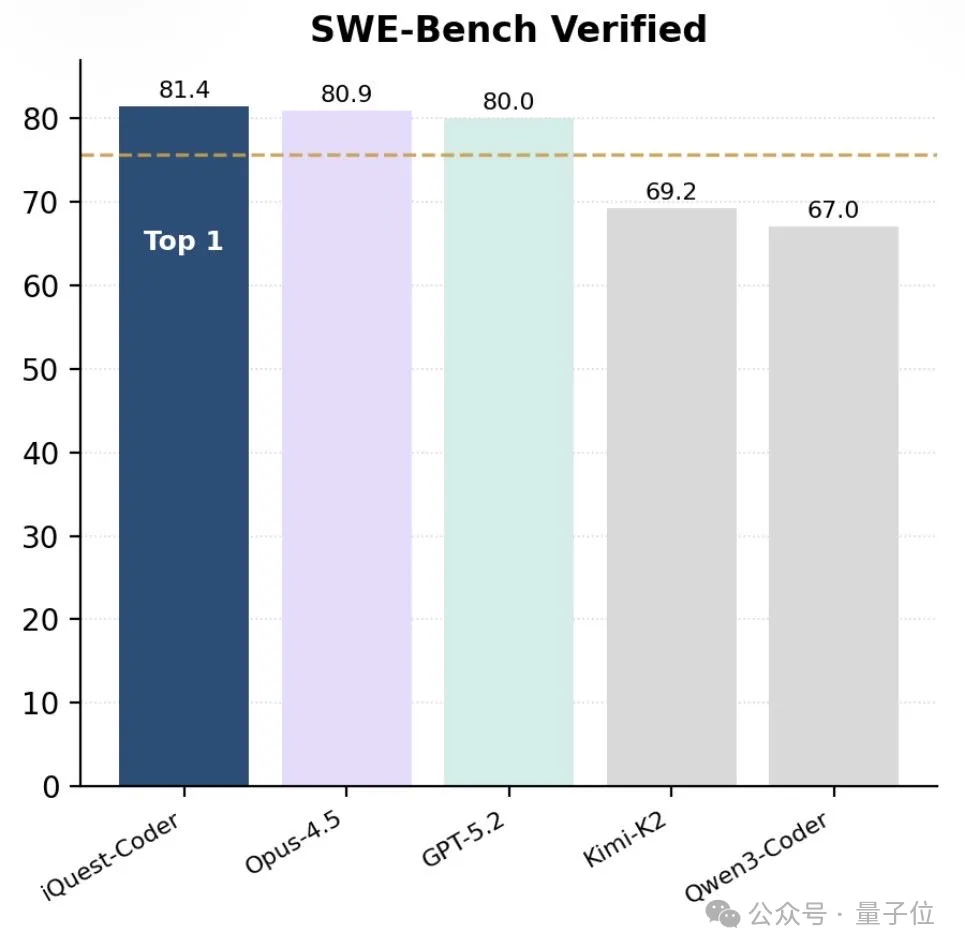
新年的第一周,AI领域便迎来一枚震撼弹。一家名为IQuest的团队悄然开源了其代码大模型系列——IQuest-Coder-V1,其40B参数版本在SWE-Bench Verified榜单上取得81.4%的惊人成绩,甚至超过了外界猜测参数规模在千亿至万亿级的Claude Opus-4.5和GPT-5.2。更令人难以置信的是,这个性能卓越的模型,仅需一张消费级RTX 3090显卡就能运行。
IQuest-Coder-V1系列提供7B、14B和40B三种参数规模,每种规模均配备Instruct和Thinking两个版本。前者注重指令遵循与工程实用性,后者则强化复杂推理能力。特别值得注意的是40B版本的Loop变体,通过创新的循环Transformer设计,在仅增加约5%训练成本的情况下,达到了数百亿参数MoE模型的水平,同时显著降低了HBM和KV Cache开销,大幅提升吞吐量。在架构设计上,该模型系列采用分组查询注意力(GQA)技术优化推理效率,原生支持128K超长上下文,能直接处理完整代码仓库与跨文件依赖。76800个token的词表大小更贴近真实代码环境,而其独特的循环Transformer设计采用两次迭代间参数共享机制,摒弃了复杂的token shifting和推理技巧,专注于提升推理稳定性。
IQuest团队摒弃了传统静态代码训练模式,创新性地提出”代码流多阶段训练”策略。他们精心设计了基于项目生命周期的三元组数据结构(R_old, Patch, R_new),仅选取项目40%-80%生命周期区间的代码变更,使模型不仅能学习代码的完成态,更能理解软件逻辑的动态演变过程。这种训练方法让模型在多个工程评测中表现出色:SWE-Bench Verified达到81.4%,BigCodeBench达49.9%,LiveCodeBench v6达81.1%。官方展示的案例更令人惊叹——从构建逼真的太阳系模拟网页,到开发具有物理交互的粒子动画;从打造像素沙盒游戏,到设计完整太空射击游戏,IQuest-Coder展现出了超越普通代码生成工具的综合能力。
与DeepSeek背后的幻方量化相似,IQuest团队源自中国量化私募巨头九坤投资。这家成立于2012年的公司,由清华大学博士王琛与北京大学硕士姚齐聪联合创立,管理规模达数百亿元人民币。九坤拥有超过百人的投研与技术团队,90%以上毕业于国内外顶尖高校,博士占比超60%。在AI领域,九坤已建立数据实验室(DATA LAB)和人工智能实验室(AI LAB),此前于2025年12月发布过通用推理模型URM。此次IQuest-Coder的发布,出自其独立研究平台至知创新研究院,核心团队成员与《Scaling Laws for Code》等知名论文作者高度重合。
目前,IQuest-Coder-V1系列已在GitHub和Hugging Face平台开源,其Int4版本支持在单张消费级3090/4090 GPU上部署,基础版和Loop版均支持单卡H20推理。这一举措在国内外AI社区引发热议,Reddit和𝕏平台上关于”中国量化公司为何能训练出如此优秀的模型”的讨论持续发酵。值得注意的是,团队明确提示模型虽能生成代码,但不能执行,输出结果应在沙盒环境中验证。这既是对安全的重视,也反映了负责任的AI发展理念。
当全球AI竞赛愈演愈烈,九坤投资这个”北京版幻方”的突然亮相,不仅展现了中国量化公司在AI领域的深厚积累,更以实际行动证明:大模型的竞争不仅是参数规模的比拼,更是架构创新与训练策略的较量。一张3090显卡跑40B参数模型的现实,或许将重新定义我们对AI硬件需求的认知,为更多开发者和研究者打开通往前沿AI的大门。
