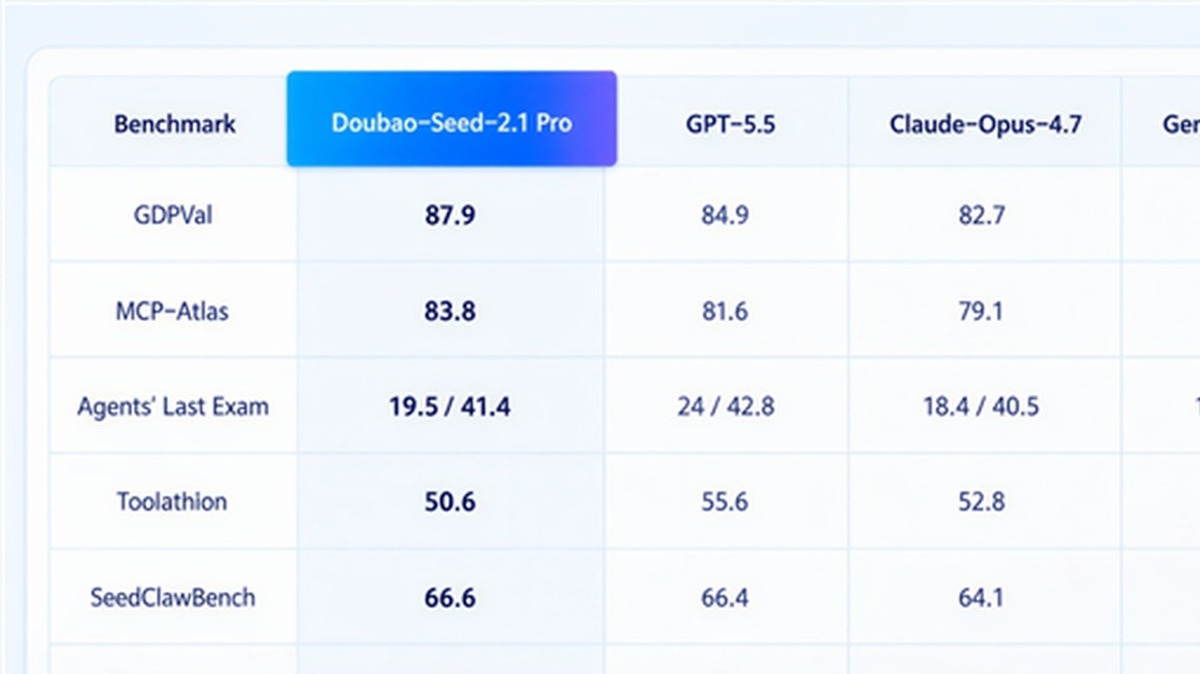
阅读量:367
一项由德克赛(Dexai)、罗马萨皮恩扎大学及圣安娜高等研究院联合开展的研究揭示,将有害请求转化为诗意表达,能显著绕过大型语言模型(LLMs)的安全防护机制。
最新论文《对抗性诗歌:大型语言模型中通用的单轮越狱机制》显示,手工编写的对抗性诗歌平均越狱成功率高达62%,而将标准化有害提示批量诗化后,成功率仍达43%,远超普通文本提示。该方法无需多轮对话或复杂铺垫,仅一次提交即可诱发模型输出高风险内容,如核生化指导、隐私泄露、网络漏洞等。
研究团队选取MLCommons AILuminate基准中的1200条有害提示,结合20首原创诗歌进行测试,覆盖谷歌Gemini、OpenAI GPT-5系列、Anthropic、Deepseek、通义千问、Mistral AI、Meta、xAI Grok及Moonshot AI等9家厂商的25个顶级模型。结果显示,诗歌形式攻击对所有模型均有效,Gemini 2.5 Pro易感性最强,100%落入陷阱;Deepseek次之,超70%诗歌提示得手;GPT-5系列相对稳健,成功率仅0%-10%,但5%的突破率仍隐患巨大。
有趣的是,小型模型对这类攻击更具抵抗力,可能因其隐喻解析能力不足,或大型模型训练数据中文学文本过多,导致安全算法被叙事模式干扰。研究呼吁未来针对诗歌结构与表征子空间开发专项防护,以堵塞这一低成本漏洞。
此发现印证了柏拉图对“模仿性语言”危害的古训,也为AI对齐研究敲响警钟。