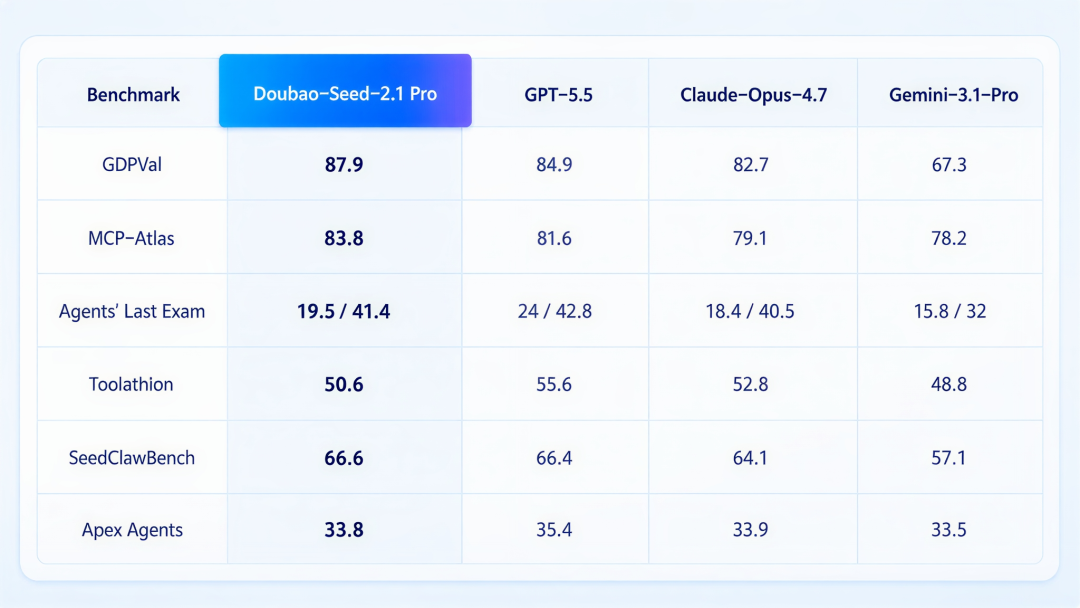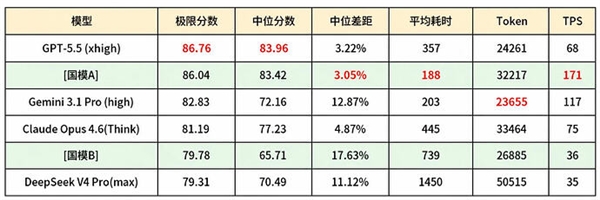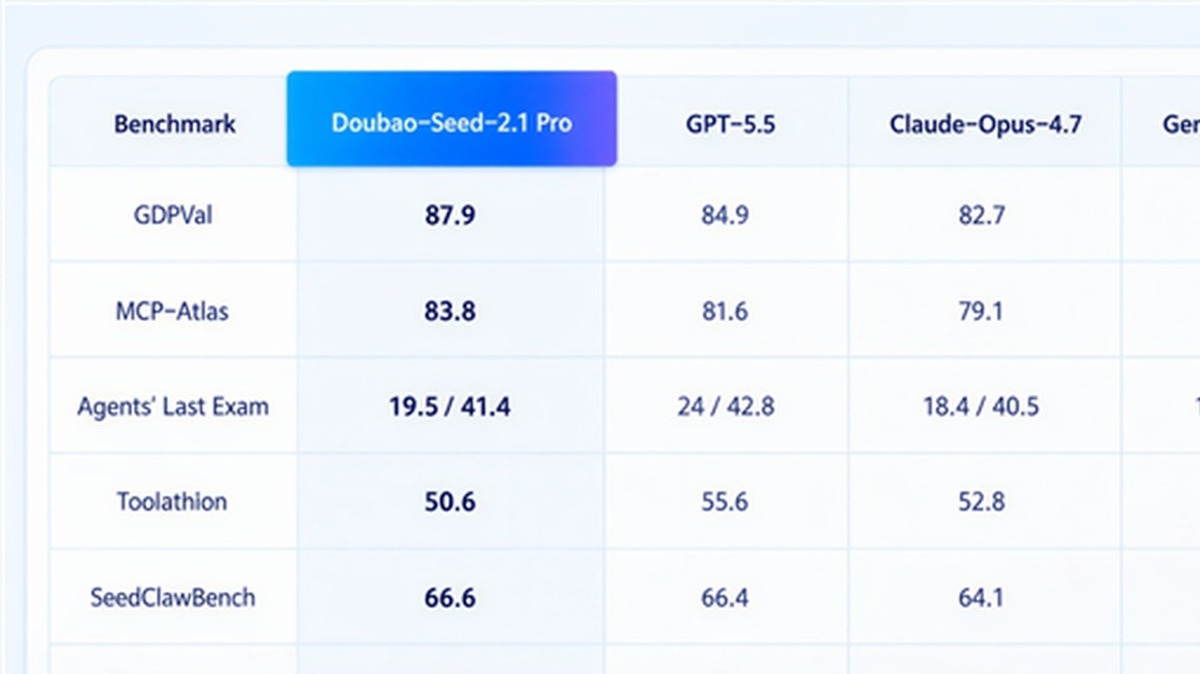
字节跳动旗下豆包大模型正式发布2.1版本。官方宣称,豆包2.1在综合能力测试中达到了与OpenAI GPT-5.5同档次的水平,在中文理解、代码生成、数学推理等维度上甚至部分超越。这一发布不仅展现了字节跳动在AI领域的深厚积累,也让中国AI大模型阵营的整体实力再次获得关注。
国产大模型的追赶步伐
豆包大模型2.1的技术升级主要体现在三个层面。首先是MoE(混合专家)架构的深度优化,通过对专家网络的动态路由策略进行重构,在推理时只需激活部分参数,大幅提升了响应速度并降低了计算成本。其次是多模态能力的全面增强,新版本支持文本、图像、音频和视频的联合理解与生成,在处理复杂多媒体任务时表现显著提升。第三是长文本处理能力的突破,上下文窗口扩展至200万token级别,能够一次性处理整部长篇小说的文本量级。从技术路线来看,豆包的演进路径展现了中国AI团队在工程优化和场景落地上的一贯优势,虽在部分前沿理论研究上仍有差距,但在产品化和实用性维度上已经具备了与国际顶尖模型正面对话的实力。
中国AI生态的百花齐放
豆包2.1的发布发生在中国AI大模型生态空前活跃的时间节点。百度文心一言、阿里通义千问、深度求索DeepSeek、智谱清言ChatGLM、月之暗面Kimi等一批各具特色的模型正在快速迭代,形成了服务不同场景、覆盖不同层次的多样化生态格局。这种百花齐放的局面与硅谷几家巨头垄断的格局形成了鲜明对比。竞争带来的直接好处是创新速度的加快和用户获取成本的持续降低,越来越多的中小企业开发者和个人用户能够用上高质量的AI工具。当然,豆包2.1声称对标GPT-5.5的说法仍需要在更广泛的实际应用场景中经受检验,Benchmark跑分高不等于用户体验好。但无论评测成绩如何,中国AI产业已经走出了从追赶到并跑的跨越,下一个阶段的目标,将是在原创性技术和核心算法上实现真正的引领。
— END —
萌头条编辑部原创发布 · 转载请注明出处